How I do architecture with AI without letting it make the decisions
A greenfield architecture workflow for the age of AI-generated code - built on OpenSpec, with guardrails that keep the AI honest.
AI can write the code in seconds now. That changed what is scarce.
For most of my eighteen years building software, writing the code was the expensive part. That is no longer true. The bottleneck moved upstream, to the decisions that come before the code. What the core concepts are. Where one part of the business ends and the next begins. What can never happen, and the edge cases that quietly break everything three features later. That is architecture, and it is now the highest-value work on the table.
It is also the work AI is worst at. Ask a model to write a function and it is genuinely excellent. Ask it to decide a system boundary and you get something confident, fluent, and sometimes wrong in a way you will not notice until it costs you a rewrite. The fluency is the trap. A wrong architecture decision and a right one come out of the model looking identical.
So there is a category of decision I never hand to a model: anything expensive to reverse. The data model and its boundaries. The trust edges - what is authenticated, what is exposed to the client, where sensitive data flows. The public contracts other systems will come to depend on. AI can draft options for these and argue them well. It does not get to decide them, because the cost of a confident-wrong answer there is a migration or a breach, not a quick edit.
That left me with a specific problem: I wanted AI to do the labor of architecture - drafting views, writing the documents, doing the review legwork - without letting its fluency make the judgment. This is a writeup of the system I built to do that, and the thinking behind each choice. I use it on a CRM I am building for my own practice; the framework is the point, not the project.
Why existing tools did not fit
I did not want to invent a methodology. I wanted to use one I already trusted: spec-driven development, specifically a tool called OpenSpec. It is disciplined and it keeps the specification in version control next to the code, which is exactly where architecture should live so it does not rot in a diagram tool nobody reopens.
But OpenSpec, like most spec-driven tooling, is built for brownfield work. You describe a change, it walks you through a proposal, the spec for that capability, a design, and a task list, then the code gets written against it. That flow quietly assumes the architecture already exists and you are extending it.
For a greenfield product, the architecture is not a given. It is the thing you are deciding, and getting it wrong is the expensive mistake. There was no workflow for "shape the high-level architecture before a single line of code." The alternatives were worse: diagram tools that lose the thinking the moment you stop opening them, or heavyweight enterprise frameworks that fight how real teams actually build, in small steps, changing course as they learn.
So I built the missing workflow on top of OpenSpec instead of around it.
The framework: architecture as a reviewable artifact
OpenSpec lets you define your own workflow (it calls them schemas). The default one ends in code. I wrote a new one, spec-driven-architecture, that ends in clarified architecture instead. It produces a coherent bundle of views as drafts, distills the durable decisions into records, then promotes the ratified result into living documentation.

Four design choices in it carry most of the weight, and each one is a judgment call about how architecture should be treated:
- The change folder is a pull request for your architecture. You shape the thinking in a sandbox, review it, and only then promote it. Architecture gets the same propose-review-merge discipline as code - the thing diagram tools never give you.
- Small changes do not pay for the big process. Each view can be marked "skip" with one line of justification, so documenting a minor boundary tweak does not force you to redraw the whole world. This is YAGNI applied to the process itself.
- Decisions are immutable once accepted. An architecture decision record (ADR), once promoted, cannot be edited. Change your mind and you write a new one that supersedes it; the old one stays frozen as history. Six months later you can see not just what was decided, but what was rejected and why. That audit trail is usually the first thing to evaporate.
- Promotion re-slices by meaning, not by file. When a view is ratified, its content is distributed into the right living documents, with exactly one copy of each fact. The canon stays readable instead of becoming a pile of duplicated drafts.
The output is real architecture, drawn with the C4 model so it zooms cleanly from "the system and the world around it" down to "the pieces that actually have to be running." Here is an actual container view this workflow produced for the CRM, simplified for readability:
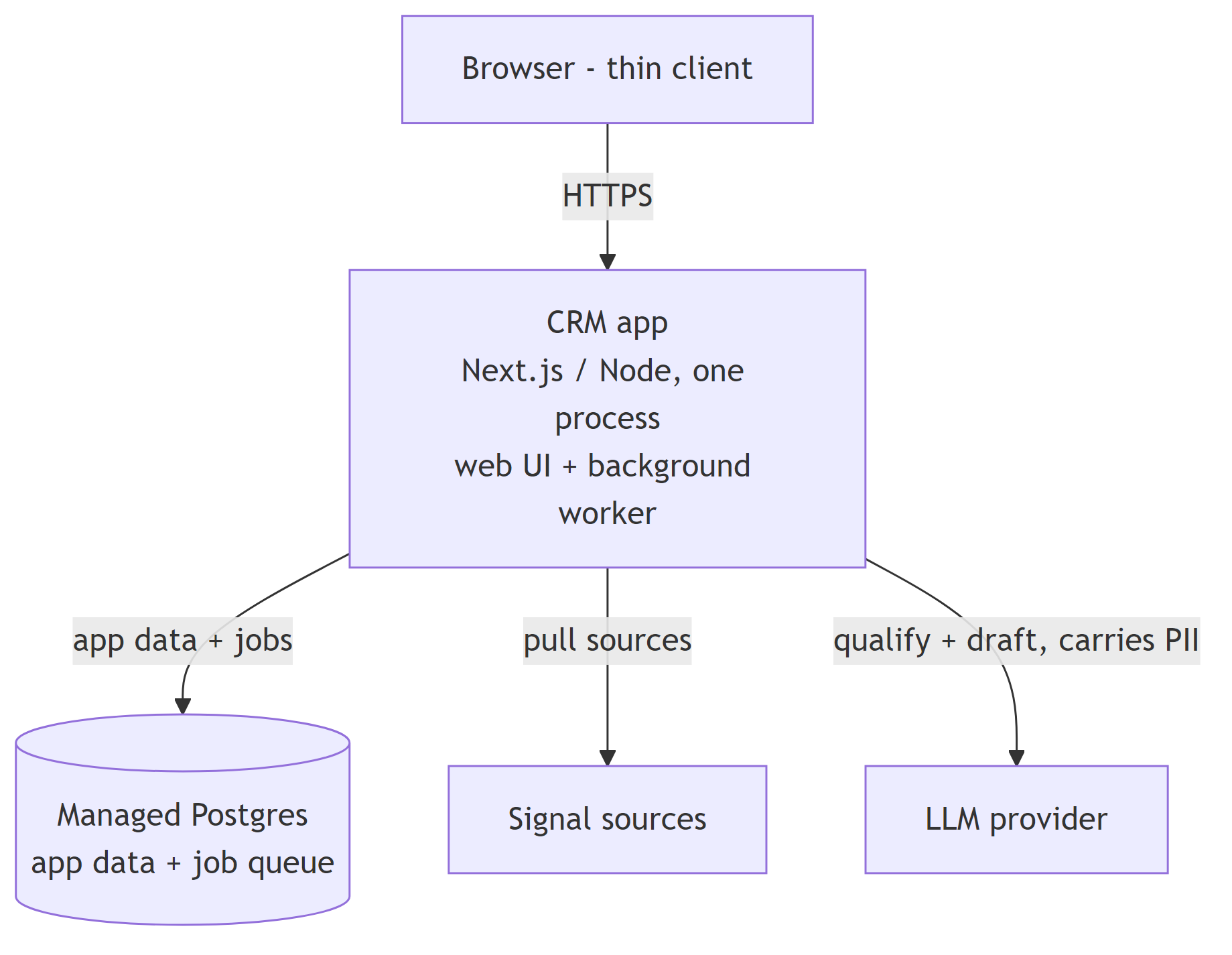
The load-bearing decision in that picture - one process running both the web app and the background worker, sharing one database - is the kind of call AI will happily rubber-stamp or over-engineer. I kept it as one container because a single-user product does not need the extra moving part, and I wrote down the exact invariant that keeps splitting it later cheap: the two halves share nothing but the database. That is a deliberate "build smart, not big" decision, documented as a decision, not drifted into.
The guardrails: where the real judgment lives
Here is the harder half. Because AI drafts these views, the workflow needed a way to stop the model's fluency from becoming my architecture. I built two layers for that, and they are where the actual AI-architecture thinking shows.
A review panel of adversarial agents. Instead of one generic "review this," I defined a roster of named reviewers, each with a single lens and the authority to read one specific source of truth. They split into two camps that are designed to disagree:
- Conformance reviewers check that a view faithfully honors decisions already made - the accepted ADRs, the locked product decisions, C4 notation discipline.
- First-principles reviewers question whether those decisions are right in the first place - a solution architect that challenges the boundaries, a senior technologist that challenges the technology choices against their real, current behavior rather than its own training memory.
When a conformance reviewer says "this conforms to our decision" and a first-principles reviewer says "that decision is wrong," the contradiction is not noise. It is the signal that a decision is genuinely live and has to be defended or replaced. A moderator surfaces that clash rather than averaging it away. The point of the panel is not consensus. It is to make the disagreements visible.
A verification gate. This is the part grounded directly in the research literature, because the failure mode here is hallucination, and hallucination is understood well enough now to handle properly rather than by vibes. Every non-trivial claim in an architecture document gets tagged by type, and each type is verified differently:
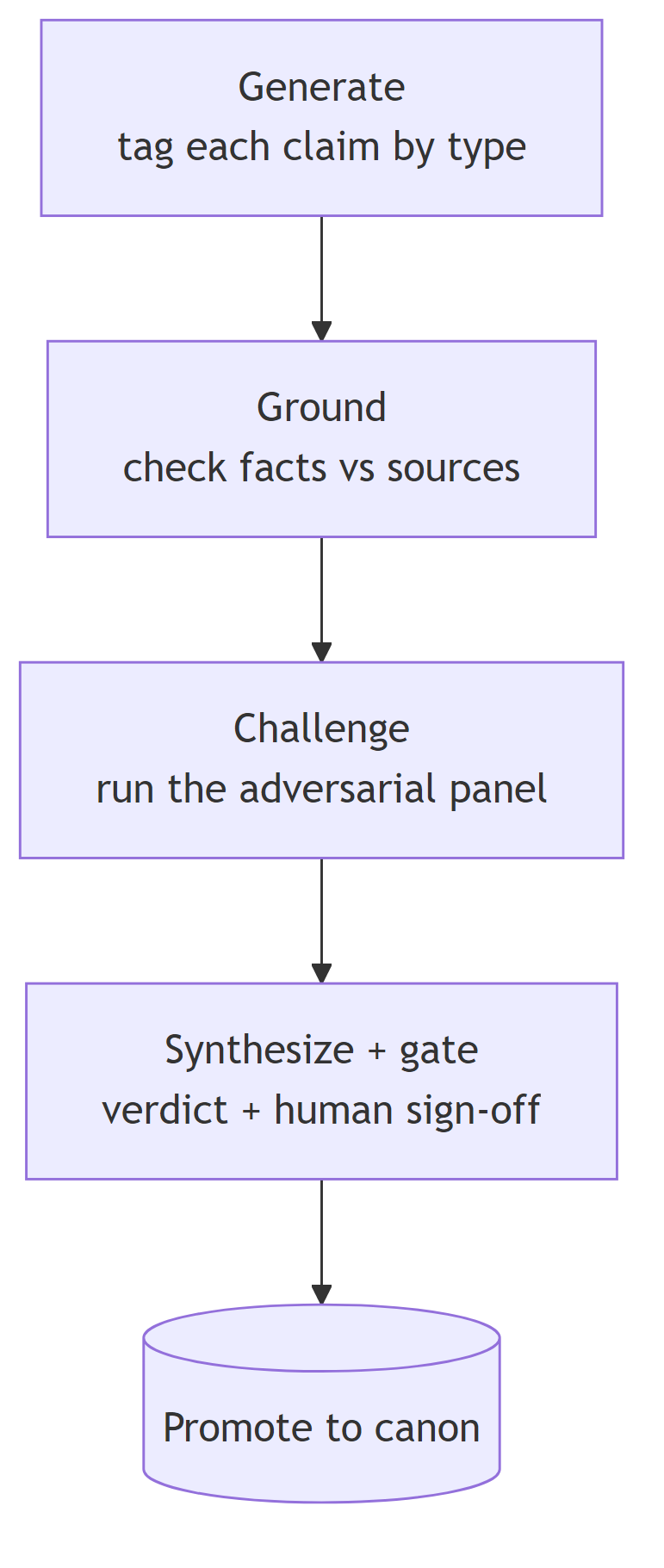
The non-obvious rules in that gate are the thinking distilled:
- Ground before you challenge. Running a design review over hallucinated content just launders the hallucination into "reviewed." Catch the fabrication first.
- Facts and judgments need different checks. A factual claim gets verified against an external source. A novel design claim, which has no source to check, gets tested for internal consistency and must be written as something falsifiable - or it does not get asserted at all. This split mirrors the extrinsic versus intrinsic distinction in the hallucination literature. [1]
- Confident errors only fall to source-checking. Consistency checks (sampling the model repeatedly and looking for divergence [2], or having it verify its own claims decoupled from the draft [3], or measuring uncertainty at the level of meaning [4]) catch what the model is unsure about. They miss what it is confidently, systematically wrong about, because the lie is stable. For those, the only defense is reading the actual source.
- Humans gate the irreversible. Automated checks cut the volume of errors but cannot own a high-stakes decision. The accepted, immutable ADRs require a human signature.
It earned its keep immediately
The first real run of the gate, against my own architecture documents, caught exactly what it was built to catch.
The AI had written a confident, specific, technically fluent justification for a database decision. It claimed that pg-boss - an open-source job-queue library that runs on Postgres - depends on a Postgres feature called LISTEN/NOTIFY. It does not. pg-boss pulls jobs by polling, with a SQL pattern called SELECT ... FOR UPDATE SKIP LOCKED. You can confirm that by reading its source in about two minutes, which is the whole point: it was a checkable fact, and nobody had checked it. The claim read perfectly, and it had sat in my architecture canon for two days. No stylistic review would have caught it. The technologist agent caught it by going and reading the source.
Then it got sharper. My first correction was also wrong - I replaced the false claim with a different confident-but-false one, this time about how database connection pooling interacts with those locks, and the gate caught that too. It took three passes to get one paragraph right, and every wrong version sounded exactly as authoritative as the correct one.
There is a second lesson I will own plainly, because it is the whole thesis in miniature. When I first designed the anti-hallucination approach, I did it from confident reasoning and cited nothing - and it was itself partly a hallucination. By the standard I was building, my own proposal failed. So I grounded the redesign in the actual research: the extrinsic/intrinsic split [1], self-consistency methods like SelfCheckGPT [2], Chain-of-Verification [3], semantic-entropy detection [4], and the human-in-the-loop requirement for high-stakes output. The system is what surfaced my own overconfidence. That is the point of building it.
The thinking, distilled
Strip away the specific tool and here is how I think about architecture now that AI writes the code. These are the principles the framework encodes:
- Architecture is the bottleneck, and where projects are won or lost. When code is cheap, the decisions before the code are where the outcome is decided. Treat architecture as a first-class, versioned artifact, not a diagram you lose.
- AI is a force multiplier for the labor, never a substitute for the judgment. Let it draft the views and do the review legwork. Keep the decisions, and the accountability for them, human - especially the ones you cannot cheaply reverse.
- Ground before you trust. The dangerous error is the confident one - fluent, specific, and wrong - and it is precisely the one that "ask the AI to double-check" will never catch. Facts get checked against real sources.
- Match the verification to the medium. Prose architecture is verified by grounding and review; code is verified by the compiler, types, and tests. One gate does not fit both, so I scoped this one to architecture and left code to its own loop.
- Make decisions durable and reversibility-aware. Record what you rejected, not just what you chose. Keep the cheap things easy to change and put a human on the things you cannot take back.
- Build smart, not big - including the process. This whole system rides on a tool I already use, adds no new infrastructure, and spends effort in proportion to the stakes. The discipline applies to the methodology as much as the product.
The scarce thing in 2026 is not AI usage. Everyone has that. It is the judgment to know when AI is helping and when it is quietly making things worse - and, more usefully, building the habits and the guardrails that make that judgment repeatable instead of a matter of luck.
That is the work I do. If you are building something new and want the architecture to be a deliberate decision rather than an accident of whatever the model generated first, this is how I approach it.
Terms used
- RAG (retrieval-augmented generation): feeding the model real documents and having it answer from them, instead of from memory.
- C4 model: a standard way to draw software architecture at increasing zoom levels, from the system in its environment down to its internal parts.
- ADR (architecture decision record): a short, dated document capturing one decision, its context, and its consequences.
- PII (personally identifiable information): data that identifies a real person and carries legal handling obligations.
- pg-boss: an open-source job-queue library that runs on PostgreSQL.
- LISTEN/NOTIFY: a PostgreSQL publish/subscribe feature - the one pg-boss does NOT use.
- SELECT ... FOR UPDATE SKIP LOCKED: a SQL technique for safely pulling jobs from a queue table so two workers never grab the same row.
References
- Tonmoy, S. M. T. I., et al. (2024). A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models (extrinsic/intrinsic split and technique landscape).
- Manakul, P., Liusie, A., Gales, M. (2023). SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. EMNLP 2023.
- Dhuliawala, S., et al. (2023). Chain-of-Verification Reduces Hallucination in Large Language Models.
- Farquhar, S., Kossen, J., Kuhn, L., Gal, Y. (2024). Detecting hallucinations in large language models using semantic entropy. Nature 630, 625-630.